高效处理H5站点流量加解密
做项目时,如果遇到上面的流量,是不是觉得有点无从下手?
今儿就看下如何使用Burpy来高效处理流量加解密。
Burpy 先来地址:Github: https://github.com/mr-m0nst3r/Burpy
直接在Release下载下来,加载到BurpSuite。
它本身的功能很简单,就是执行我们指定的python脚本,而python脚本能用来干啥,你可以百度一下(你能想到的,基本都能做到)。
大概的实现是这样的:
启动一个RPC服务器,作为Java和Python之间的数据交换桥梁
解析python脚本,并新建Burpy类的一个实例
将脚本中的一些函数加载到BurpSuite右键菜单
当点击Burpy菜单项时,整个HTTP数据包通过RPC传给python脚本的对应函数进行处理,返回处理后的HTTP数据包,并更新BurpSuite
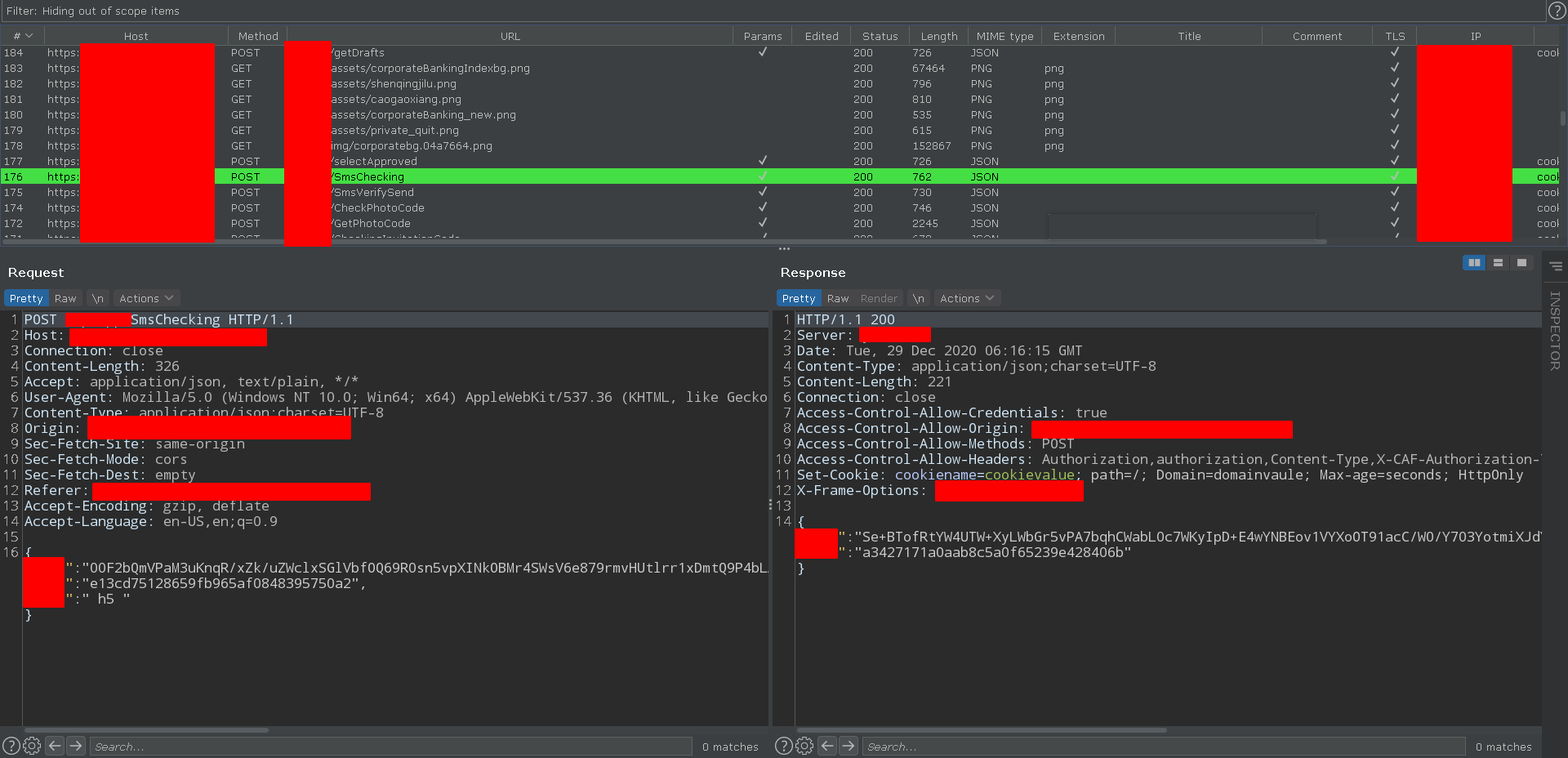
分析目标 这是个Webpack之后的H5界面,前端使用VueJS编写的:
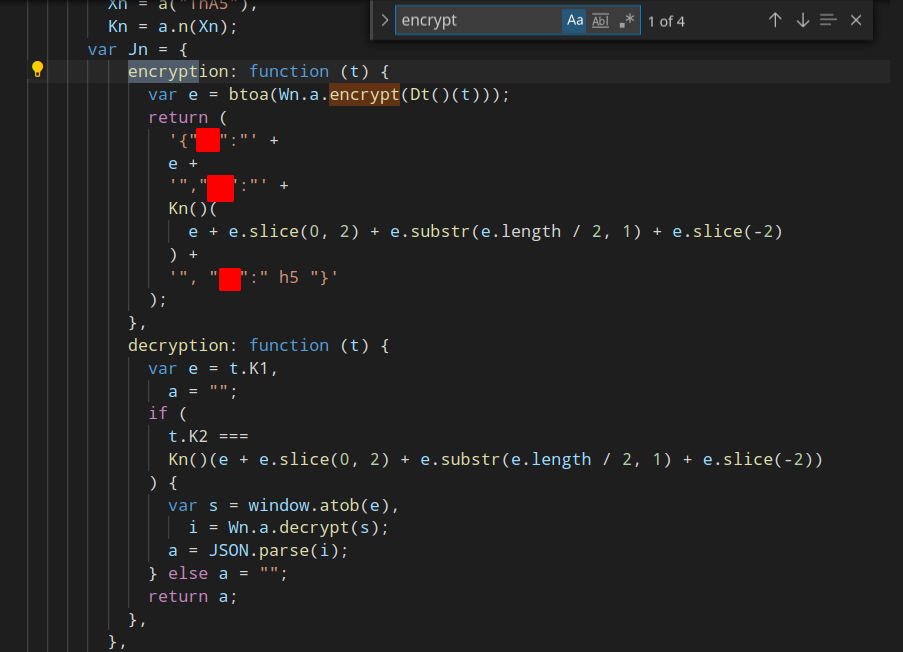
我们将上面的几个JS脚本文件下载到本地,使用prettier进行美化格式之后,用VS Code打开,然后查找encrypt:
大概看了一下,Wn.a.encrypt是加密函数,Wn.a.decrypt是解密函数。
解密时有两个参数,K1和K2,K1就是密文,K2是通过一个计算(md5)K1变换之后与提交的K2是否相等,如果相等就进行解密,是一个解密带签名的操作。
加密时,将数据进行加密之后进行base64编码,构造K2的值,然后构造数据包。
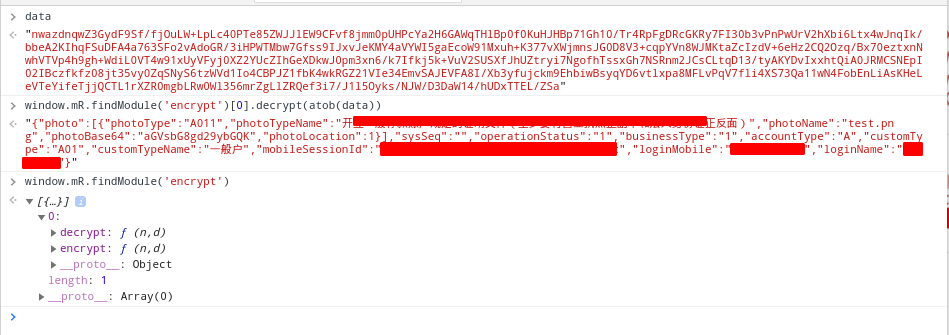
ModuleRaid.js 这个工具脚本的功能不详,不过提供了一个非常有用的方法:findModule。
用浏览器打开目标网站,F12打开检查,将ModuleRaid.js复制到console里面,回车,我们就能通过window.mR来使用它了。
思路 我们已经可以从浏览器中正常加解密数据了,但是如果让我们在浏览器/BurpSuite中间复制来粘贴去的,这活我干不了,想想都头疼。这时候就是Burpy大显身手的时候了。
我们不需要在python里面实现这个算法是如何实现的,不需要使用python重写加密和解密代码,只需要直接调用就好了。
但直接调用的时候,就像上面,是在浏览器中啊,怎么办?selenium~
我们要达到的目的是:
轻轻一点,解密出来,修改数据包
再轻轻一点,加密,点击GO发送
再轻轻一点,解密,看看返回包
或者更好一点:
一点解密,修改数据包
点GO,自动加密
收到返回包之后自动解密出来显示在BurpSuite里
第二种情况下,加密解密已经透明了。
值得高兴的是,这些功能,Burpy都支持。
编写脚本 Burpy脚本的框架在Github里面有,各位自己看一下,很简单明了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 from selenium import webdriverimport jsonimport hashlibchromeExec = "/usr/bin/chromedriver" url = "https://xxxx.com/yyyy/zzzz" class Burpy : def __init__ (self ): """ this is called from the start of PyRo4 service, so init webdriver here """ option = webdriver.ChromeOptions() option.add_argument('headless' ) self.driver = webdriver.Chrome(executable_path=chromeExec, chrome_options=option) self.driver.implicitly_wait(20 ) self.driver.get(url) self.k1 = '' self.k2 = '' self.k3 = ' h5 ' try : js = self._load_js() self.driver.execute_script(js) except Exception as e: print ("Failed to load MouldueRaid JS" ) print (e) def __del__ (self ): self.driver.quit() def _load_js (self ): jsFilePath = r"/home/m0nst3r/tools/moduleraid.js" with open (jsFilePath) as f: jsContent = f.read() return jsContent def decrypt (self, header, body ): bodyjson = json.loads(body) self.k1 = bodyjson.get('K1' ) self.k2 = bodyjson.get('K2' ) DecRes = """return window.mR.findModule('encrypt')[0].decrypt(atob('%s'))""" % (self.k1) result = self.driver.execute_script(DecRes) print ("Dec Res: " , result) nbody = result return header, nbody def encrypt (self, header, body ): EncRes = """return btoa(window.mR.findModule('encrypt')[0].encrypt('%s'));""" % (body) result = self.driver.execute_script(EncRes) e = result + result[0 :2 ] + result[int (len (result)/2 )] + result[-2 :] m = hashlib.md5() m.update(e.encode('utf-8' )) self.k2 = m.hexdigest() resjson = {} resjson.update({"K1" :result}) resjson.update({"K2" :self.k2}) resjson.update({"K3" :self.k3}) res = json.dumps(resjson) res = res.replace(" " ,"" ) print ("Enc Res: " , res) return header, res
代码就是最好的注释了。
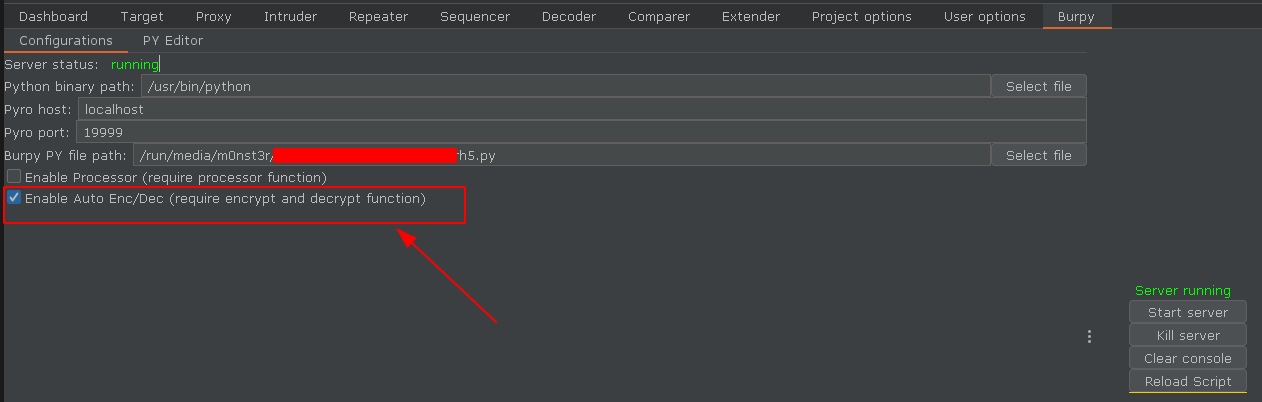
使用selenium和webdriver的环境搭建就不多说了,很简单。值得注意的是,如果把webdriver初始化的方法放到函数中,会在BurpSuite中出现卡顿的现象,因为webdriver启动加载我们指定的URL时需要时间,把这个初始化过程放到类的__init__函数中,在start server时会卡几秒,之后就会非常流畅。(这也是Burpy脚本要写成Python类的主要原因)
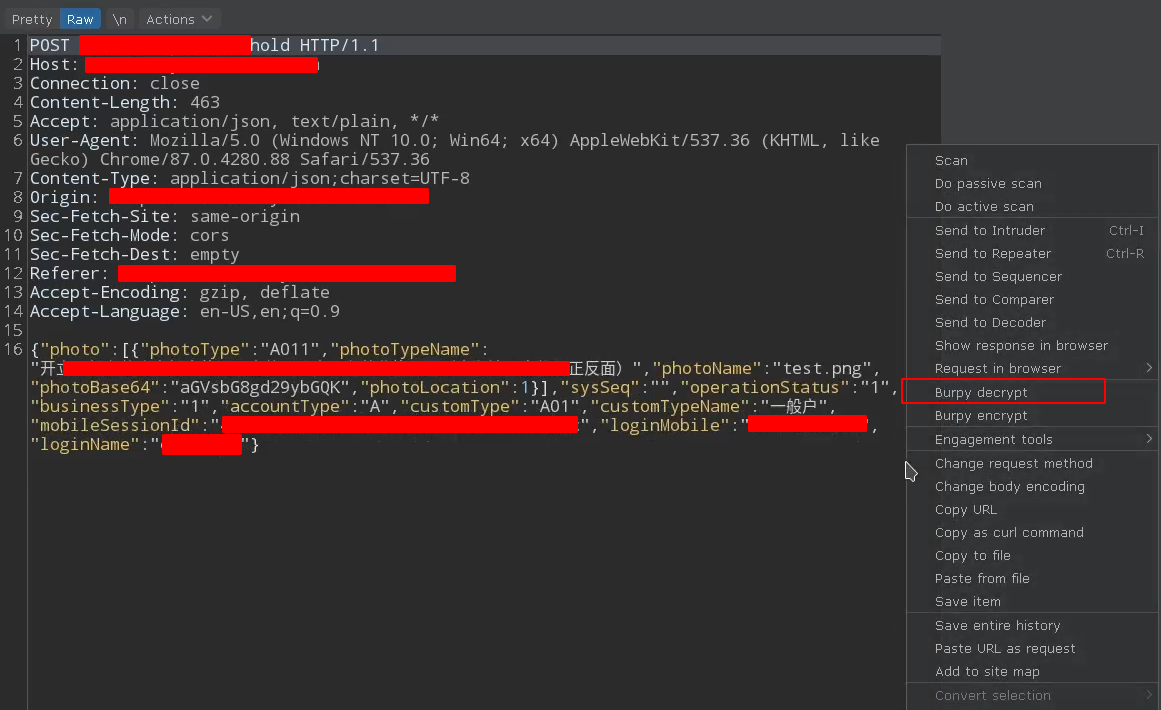
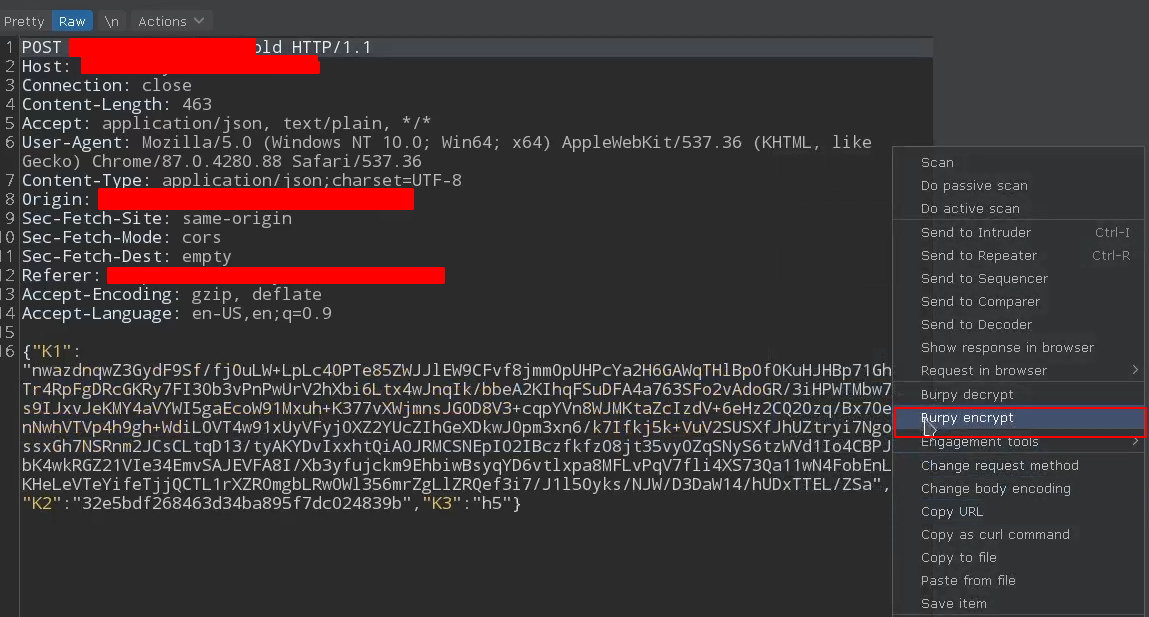
效果 点击解密:
点击加密:
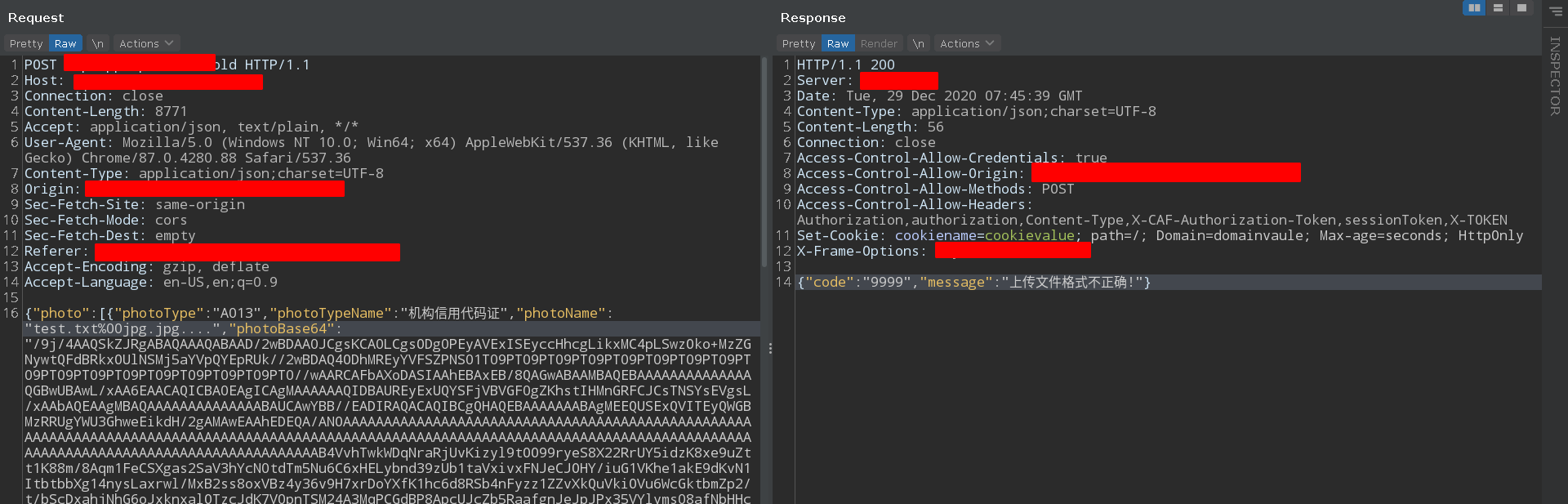
自动加解密:
总结 到此,加密的流量变成了明文,妈妈再也不用担心我无法进行渗透测试了!